Best Google Text to Speech Alternatives in 2026
Looking for Google Text to Speech alternatives? Discover top AI Text-to-speech solutions with features like ultra realistic voices, voice cloning, translations and more. Popular alternatives to Google Text to Speech include Fliki, Murf AI, PlayHT, and Typecast, ensuring you find the best fit for your needs.
About Google Text to Speech
Google's Text-to-Speech is a highly acclaimed text-to-speech service. It was launched in August 2018 and utilized Google's robust neural network, powered by DeepMind, one of the most advanced AI algorithms available. It offers scalability and can be applied to various applications, from simple tasks like Google Voice search on Android phones to global implementations like chat and voice-based customer service. Developer teams can leverage its API integrations to create comprehensive solutions combining text-to-speech and speech-to-text capabilities.
Best Alternatives to Google Text to Speech
1. Fliki
What is Fliki?
Fliki is an AI-based text-to-speech conversion tool that can also convert text into videos. It leverages AI and machine learning to produce high-quality audio that sounds closest to a human.
The tool offers over 2500 voices, each with a demo to help you select the right voice for your content. With support for over 80 popular languages and 100+ dialects, Fliki is an affordable solution for a wide range of audio and video content creation needs.
Whether you need to create voiceovers, host a podcast, produce an audiobook, or generate a video from text, Fliki can accommodate most of your needs.
Who is Fliki for?
Fliki is designed for a wide range of users who want to create high-quality audio and video content easily.
It is perfect for business owners seeking to create engaging content for their social media channels, content creators looking to produce videos more efficiently, or anyone in between who wants to create and share their audio and video content.
One key feature that sets Fliki apart is its text-to-video feature, making it the only tool in the list that offers this capability. This makes it particularly suitable for YouTube content creators, social media influencers, and other content creators looking to produce visually engaging videos to accompany their audio content.
Key features of Fliki:
2500+ realistic voices
80+ languages with 100+ accents
Ultra Realistic Voice Cloning
In-built Translations
Background Music
Pronunciation Map
Text to Video Capabilities
Pros of Fliki:
Simple interface and workflow
Voice quality is excellent, even in regional languages
Supports adding pauses, changing pitch, tone and emotions
Text to video capabilities adds cherry on top
Customer support is fast and friendly
Cons of Fliki:
Their credit consumption model is a little complex
Rating:
Pricing:
Free
Standard - $28/month
Premium - $88/month
Free
5 minutes of audio and video content (720p)
Access 300 voices
Access 80+ languages & 100+ dialects
Access thousands of images, video clips and music assets
Create audio and videos from blog articles, PDFs, PPTs and product urls
Generate images using AI
Create up to 10 scenes per file
Standard - $28/month
180 minutes of audio and video content
Access 1000 voices including 150 ultra-realistic
Access 80+ languages & 100+ dialects
Translate audio and video to 80+ languages
Create videos using text (1080p Full HD)
Access thousands of music assets
Pronunciation map
Create up to 50 scenes per file
Commercial rights
Access to premium community
Access millions of images, video clips, and music assets
+ Everything in Free Plan
Premium - $88/month
600 minutes of audio and video content per month
2000+ voices including 1000+ ultra-realistic
Faster exports
Multiple brand kits
Multiple voice cloning
Multiple custom voices
Generate AI video clips
All AI avatars
Photo avatars
Priority email & chat support
+ Everything in Standard Plan
2. Murf AI
What is Murf AI?
Murf.ai is a cutting-edge voice-generation tool that leverages AI technology to generate realistic voiceovers. It has a user-friendly interface and a library of 130+ AI voices across multiple languages and accents.
Murf also allows customization, allowing users to experiment with the delivery and intonation of the premium voices available. Users can tailor the voiceover to their specifications with features such as adjusting tone and pitch, introducing punctuation, and adding emphasis.
The platform offers an array of AI tools, including a Voice Changer feature, Voice Editing, Time Syncing, and a Grammar Assistant. With Murf, users can seamlessly produce high-quality voiceovers, whether they have the ideal tone/accent or not.
Who is Murf AI for?
A wide range of audiences can use Murf. It can be helpful for educators who want to create e-learning videos and tutorials. Content creators can also use it to create videos for platforms such as YouTube or explainer videos and other audio and video content.
Businesses can also benefit from Murf's AI voiceover feature, as it enables them to generate custom voices for various needs, such as ads or presentations, instead of hiring a voice actor.
Murf also provides text-to-speech functionality, which allows users to convert written text into speech. The tool uses human-like voices, creating an enjoyable listening experience.
Key features of Murf AI:
120+ voices
8000+ licensed soundtracks
Transcription
Collaborative Workspace
AI Voice Changer
Pros of Murf AI:
Well organized and easy to access all of their voices
Easy to use interface
Offers a variety of different voices in a variety of languages
Cons of Murf AI:
Voice quality is still not perfect and can sound robotic.
Pronunciation errors are not uncommon.
Higher cost compared to some alternatives.
Pricing:
Basic - $29/user/month
Pro - $39/user/month
Enterprise - $59/user/month
Free
No downloads
Try all 120+ voices
10 mins of voice generation
10 mins of transcription
Share link for audio/video output
Single User
No credit card required
Basic - $29/user/month
Access to 60 basic voices
Access to 10 languages
24 hours of Voice generation per user/year
Collaborative Workspace
No AI Voice Changer
Commercial usage rights
8000+ licensed soundtracks
Chat & Email Support
Pro - $39/user/month
Access to all 120+ voices
All 20+ Languages & Accents
4 hours of voice generation per user/month
2 hours of transcription per user/month
Collaborative Workspace
AI Voice Changer
Commercial Usage Rights
8000+ licensed soundtracks
High Priority Support
Enterprise - $59/user/month(Min. $3540 billed annually only)
5+ Users
Unlimited Voice generation, Transcription & Storage
Collaboration & Access Control
Dedicated Account ManagerService Agreement
Security Assessment
Single sign-on (SSO)
Training & Onboarding Support
PO & Invoicing
Deletion recovery
+ Everything in Pro Plan
3. PlayHT
What is PlayHT?
Play.ht is a web-based platform for generating high-quality text-to-speech. With its user-friendly interface, users can type in their text, and select their preferred language, voice style, and speed to generate speech quickly.
Play.ht offers over 907 AI voices supporting 142 languages, making it suitable for personal and commercial use. Additionally, it can fine-tune speech tone with voice inflections and customize speech pronunciations.
Play.ht also offers podcast hosting capabilities, allowing users to publish their podcasts to major platforms like iTunes, Spotify, and Google Podcasts. Additionally, users can convert their WordPress blog posts directly into audio files using their WordPress plugin.
Who is PlayHT for?
Play.ht is a powerful tool for those who require high-quality voiceovers for their projects. Whether it is for videos, podcasts, e-learning, or other needs, Play.ht is a reliable option.
In addition to voiceovers, Play.ht also offers text-to-speech functionality, allowing users to convert written text into speech using synthetic voices. It can increase the accessibility of the content and enhance user engagement.
Overall, Play.ht is a versatile and convenient tool for content creators, businesses, and individuals who require realistic voiceovers and text-to-speech capabilities for their projects.
Key features of PlayHT:
907 AI Voices
Voice Inflections
Custom Pronunciations
Speech Styles
Multi-Voice Feature
Pros of PlayHT:
Allows to add team members
Quality of voices is amazing
Premium voices in multiple languages and accents
Cons of PlayHT:
Have to upgrade to expensive plans to use premium voices
Some features like pronunciation library are only available to premium users
French voiceovers tend to make unnecessary liaisons (e.g. "ils ont été", "ça aurait été")
Rating:
Pricing:
Personal - $19/month
Professional - $39/month
Premium - $99/month
Free
⚠️ PlayHT does not offer any free plan.
Personal - $19/month
20,000 words per month
Standard Voices
Audio Previews
Audio Downloads
Professional - $39/month
50,000 words per month
Premium Voices
Audio Previews
Unlimited Downloads
Unlimited Projects
Commercial License
Premium - $99/month
500,000 words per month
Ultra realistic Voices (beta)
Standard & Premium Voices
Pronunciations Library
White-labelled Audio Players
Unlimited Audio Previews
Unlimited Downloads
Unlimited Projects
Commercial License
4. Typecast
What is Typecast?
Typecast is a voice generator and video editing software that uses AI technology. It provides services for a diverse range of audiences and allows the creation of a wide variety of content, such as audiobooks, educational videos, sales videos, documentaries, and training videos. The platform has two main tools: Typecast Audio and Typecast Video.
Typecast Audio provides the ability to generate text-to-speech audio in over 300 voices. Users can type or upload a script, adjust the tone and delivery, and choose from available templates for different use cases.
Typecast Video integrates AI speech synthesis with videos to create virtual characters and experiences. By inputting video transcripts, users can create voice-generated videos. Additionally, users can adjust the facial expressions of their virtual voice actors.
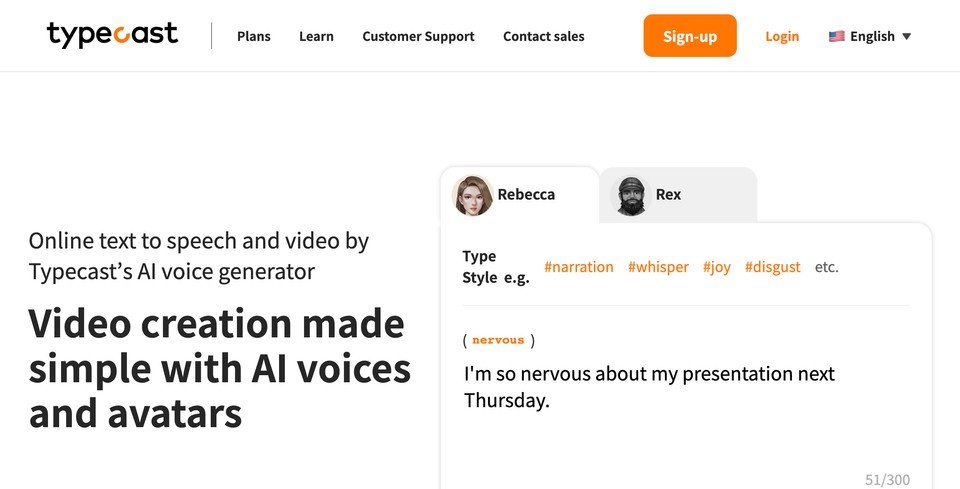
Who is Typecast for?
Typecast.ai is a software tool designed to help creators and businesses generate AI-generated voices for various uses, such as branding, games, animated films, audiobooks, and voice assistants.
Typecast.ai is a valuable tool for writers, journalists, YouTubers, and other content creators who produce their ideas and information. They can use the service to convert their written content into audio files.
The technology behind Typecast.ai, provided by Neosapience, allows users to produce a range of sounds in real time, eliminating the need for voice recording. It makes Typecast.ai a convenient and efficient solution for creating high-quality audio content.
Key features of Typecast:
Detailed Speech Control
Import External Files(.pdf, excel, ppt, epub)
Multi-User Support
Collaborative Features
Custom API Access
Pros of Typecast:
Wide variety of emotions and tones that AI voices can convey.
Ability to adjust the tone and emotion of the voice to create unique voiceovers.Intuitive user interface that makes it easy to use even for beginners.
High quality and realistic AI voices.
Cons of Typecast:
Free plan offers limited trial characters(voices)
Complex pricing structure with feature lock-ins!
No customer reviews on g2, capterra, etc
Pricing:
Basic - $8.99/month
Pro - $39.99/month
Business - $89.99/month
Free
Individual user
3 minutes of monthly download time
Can use trial characters
Basic - $8.99/month
Individual user
30 minutes of monthly download time
5 minutes of monthly virtual human download time
Can use all characters
Can load external files (Excel, PDF, TXT, EPUB)
+ Everything in Free Plan
Pro - $39.99/month
2 hours of monthly download time
20 minutes of monthly virtual human download time
Detailed speech control
High quality audio download
High quality video download
+ Everything in Basic Plan
Business - $89.99/month
6 hours of monthly download time
1 hour of monthly virtual human download time
Can purchase additional download time
Can share projects
Can purchase additional team member slots
+ Everything in Pro Plan
5. Resemble
What is Resemble?
Resemble is a text-to-speech software that leverages AI technology to clone and generate synthetic voices in real-time. The software offers options for specific use cases such as advertisement and dialogue audio, brand voices for virtual assistants and IVR systems, and instant language dubbing.
With Resemble AI, businesses can create custom brand voices for virtual assistants and personalize them for call centers. The platform features four synthetic voice-generating options, a vast voice actor library, language dubbing, and one-click text generation for advertisements.
Users can create AI voices by recording on the website, uploading raw files, using APIs, or selecting from the company's market of voice actors.
Who is Resemble for?
Resemble.ai is a text-to-speech tool that allows users to convert written text into speech using its high-quality AI voices. It operates on a pay-as-you-go model for custom voices built on the platform.
It makes Resemble.ai a flexible and cost-effective solution for anyone looking to generate speech from written text. Whether you're creating podcasts, audiobooks, or other forms of audio content, Resemble.ai has you covered.
In conclusion, Resemble.ai is a convenient and user-friendly tool that offers a pay-as-you-go model for its custom voices, making it a cost-effective solution for creating audio content from written text.
Key features of Resemble:
Emotion Control
API Access
AI-Generated Text
Mobile Deployment
Enterprise SLAs
Pros of Resemble:
Offers numerous synthetic voices that sound good
Allows customization of voice emotions
Easy to use with a simple UI
Option to download audio files (wav or mp3) and access to API for easy integrations
Includes a voice cloning feature
Cons of Resemble:
No free version, only 7-day trial period with subscription required
Two subscription plans with the cheaper version being pay-as-you-go and limited in features
The Basic version limits access to voices and language options
Voices can sound too robotic and not as lifelike as other TTS apps
Rating:
Pricing:
Basic - $0.006/second
Free
⚠️ Resemble does not offer any free plan.
Basic - $0.006/second
$0.006 per second
Web-Recorded Custom Voices
Up to 10 Voices
English Only
50+ Marketplace Voices
Unlimited Audio Downloads
Pay as you go
6. Lovo
What is Lovo?
Lovo.ai is an AI-powered text-to-speech software for various applications such as animation voiceovers, eLearning, audio ads, audiobooks, gaming, and more.
It offers two main modules - Lovo Studio and Lovo API - that cater to businesses and individuals looking for voice AI solutions for their marketing and customer service needs.
With Lovo, users can create custom voices that sound human, overcoming language barriers and helping to establish brand identity. The Lovo Studio offers a wide range of voice options, while the Lovo API allows real-time conversion of texts into speech in 33 different languages.
With Lovo, users can create unlimited audio files and refine their voiceovers until they are perfect.

Who is Lovo for?
Lovo is a synthetic speech platform that provides advanced AI voiceovers and text-to-speech services for various industries, including e-learning, marketing, and entertainment. With its cutting-edge technology and natural-sounding voices, Lovo is an ideal solution for businesses and individuals looking to produce high-quality audio content.
Lovo is targeted explicitly towards marketers, e-learning course creators, and YouTubers who require voiceovers for their videos or training materials. It offers a vast selection of voices covering over 100 languages and dialects, making it a highly versatile option for a wide range of projects.
In conclusion, Lovo is an excellent synthetic speech platform that provides advanced AI voiceovers and text-to-speech services. It is a valuable tool for businesses and individuals looking to create high-quality audio content.
Key features of Lovo:
400+ Global Voices
100+ Languages
Video Dubbing
Emotion Control
Commercial Rights
Video Export
Pros of Lovo:
Add background music to the voices
Provides options for selecting a Character based on emotions
Output of voices is quite realistic
Cons of Lovo:
UI/UX feels plain and boring
Choice of voices is bit limited
A handful of voices sound robotic
Rating:
Pricing:
Pro (2 hours) - $30/month
Pro (5 hours) - $48/month
Free
20 minutes of Voice Generation
Watermarked video export
1GB Storage
No Commercial Rights
Pro (2 hours) - $30/month
2 Voice Generation Hours / mo
400+ Global Voices in 100+ Languages
60+ Emotional Voices
20+ Premium Voices1080p video export
Finegrained Emotion Control
Video Dubbing
30GB Storage
Unlimited Downloads
Commercial Rights
Pro (5 hours) - $48/month
5 Voice Generation Hours / mo
400+ Global Voices in 100+ Languages
60+ Emotional Voices
20+ Premium Voices
1080p video export
Finegrained Emotion Control
Video Dubbing
30GB Storage
Unlimited Downloads
Commercial Rights
7. Listnr
What is Listnr?
Listnr is an innovative AI-powered text-to-speech solution that provides high-quality voice outputs in over 75 languages and 600 human-like voices. With its built-in editor, you can make adjustments such as adding pauses and changing pronunciations.
Listnr offers the option to generate a custom audio player that can be embedded into websites, making it a valuable tool for creating and managing podcasts. The tool supports advertising for monetization purposes and the distribution of audio content on platforms such as Spotify, Apple, and Google Podcasts.
Who is Listnr for?
Listnr.tech is suitable for a wide range of applications and has been particularly helpful for e-learning, podcasts, videos, presentations, and marketing.
Content creators, educators, and businesses can use the software to generate high-quality speech in real-time and save time and effort compared to manual recording.
The software's user-friendly interface and integration with various platforms make it an excellent option for anyone who wants to create high-quality speech content.
Key features of Listnr:
TTS Editor
Podcast Hosting
AI Podcast
Audio Player
Text to Speech API
Pros of Listnr:
Saves time in creating audio-based content from existing posts
Natural sounding voices
Built-in audio embedding feature
Many languages and accents to choose from
Cons of Listnr:
Can have bugs or lag with big text
Experienced a bug that caused a user to lose words from their balance
Some accents are more elaborate than others
Automatic failures can occur, requiring manual correction.
Pricing:
Individual - $19/month
Solo - $39/month
Startup - $59/month
Free
⚠️ Listnr does not offer any free plan.
Individual - $19/month
10,000 words/mo
Unlimited Downloads/exports
25GB Storage
Access to all 600+ voices
Unlimited Audio embeds
Solo - $39/month
30,000 words/mo
Unlimited Downloads/exports
50GB Storage
Access to all 600+ voices
Unlimited Audio embeds
Startup - $59/month
100,000 words/mo
Unlimited Downloads/exports
100GB Storage
Access to all 600+ voices
Unlimited Audio embeds
8. FakeYou
What is FakeYou?
FakeYou is an online tool that utilizes deep fake technology to generate custom voiceovers from text inputs. With a vast library of 3,000 voices, the platform offers a wide range of options for users looking to imitate celebrities, characters, and even regular people.
Whether you're looking to enhance your content or add a unique touch to your project, FakeYou provides a versatile solution for voice generation. Featuring an intuitive and user-friendly interface, FakeYou leverages AI algorithms to generate convincing voiceovers. The platform continues to improve its output quality with regular updates. Users can also edit and save their creations in popular file formats for later use.
Who is FakeYou for?
FakeYou is a free online text-to-speech platform that allows users to create AI-based deep fakes using machine learning. The software offers over 3,000 voice cloning options to imitate famous cultural figures, celebrities, and characters from movies and TV shows. FakeYou also supports open-source voice models.
It's important to note that while the tool may be used for entertainment purposes, creating deep fakes can have severe consequences and is not intended for dishonest behavior. Misusing deep fakes can lead to ethical and legal issues, and it's crucial to consider the potential impact on individuals and society before using this technology.
Key features of FakeYou:
Voice Cloning
Video Lipsync
Multi-Language Voice Support
Upload Private Voice Models
Pros of FakeYou:
Easy to use interface with a text box and a "Speak" button
Wide selection of voices (3000+ options) with the ability to search for specific voices
Option to clear the text box and try different textsBased on voice cloning technology
Cons of FakeYou:
Voice quality may not be as good as other text-to-speech tools that use AI and machine learning technology
Voice selection may not be as diverse or customizable as other text-to-speech tools
Dependent on community contributors for voice building, which may result in inconsistent quality or limited options.
Pricing:
Plus - $7/month
Pro - $15/month
Elite - $25/month
Free
⚠️ FakeYou does not offer any free plan.
Plus - $7/month
Normal Processing Priority
Up to 30 seconds audio
Unlimited generation
Wav2Lip - Up to 1 minute video
Pro - $15/month
Faster Processing Priority
Up to 1 minute audio
Unlimited generation
Upload private models
Wav2Lip - Up to 2 minute video
Elite - $25/month
Fastest Processing Priority
FakeYou Commercial voices
Up to 2 minute audio
Unlimited generation
Upload & Share private models
Wav2Lip - Up to 2 minute video
9. Speechify
What is Speechify?
Speechify is a reading app and chrome extension that aims to assist in reading for two core purposes: to improve reading speed and to help individuals with reading difficulties such as ADHD and dyslexia.
The cloud-based solution is limited in generating new speech, but Speechify offers a text-to-speech API for businesses. This API helps increase engagement and accessibility for content publishers.
The app features various customization options, including multiple playback speeds, text highlighting, natural-sounding voice accents, and celebrity voices.
Who is Speechify for?
Speechify is a cutting-edge TTS app designed for individuals who want to efficiently and comfortably read digital or physical texts. With its innovative technology, Speechify transforms written material into natural-sounding speech, making reading more accessible and engaging.
Users with a library of over 50,000 audiobooks and documents have a vast selection of reading materials. Additionally, Speechify offers the option to convert text into audio files for later listening.
Speechify has quickly gained popularity with over 10 million users; available as a Google Chrome extension and mobile app for iOS and Android. This app is ideal for students, professionals, and anyone looking to boost their productivity and reading experience.
Key features of Speechify:
30+ voices
15+ languages
5x faster listening speeds
Advanced highlighting, note taking, and importing tools
60,000+ audiobooks
Pros of Speechify:
Clean and intuitive interface for multiple platforms (desktop, Chrome app, and mobile)
Efficient and friendly customer support
Control speed of voices easily
Cons of Speechify:
Minor bugs exist, but quickly fixed by the company
Limited features with the free plan, upgrade to premium required for full benefits.
Pricing:
Premium - $139/year
Audiobooks - $199/year
Free
10 standard reading voices
Listen at speeds up to 1x
Text to speech features only
Premium - $139/year
30+ reading voices
20+ languages
Scan and listen to any printed text
Listen at 5x faster speeds
Advanced skipping and importing
Highlighting + note taking tools
Audiobooks - $199/year(Bundle with Text to Speech for $249/y)
Actor-narrated audiobooks
1 free credit with trial
12 credits per year
Access to 60,000+ titles
Newest releases
All best-sellers 1000's of free audiobooks
10. Amazon Polly Text to Speech
What is Amazon Polly Text to Speech?
Amazon Polly Text to Speech is a cloud-based service that converts text into realistic speech. It utilizes advanced deep-learning technologies to produce natural-sounding speech. Amazon Polly has gained widespread acceptance in various industries, such as entertainment, marketing, contact centers, assistive apps and devices, and personal voice assistants.
Who is Amazon Polly Text to Speech for?
Amazon Polly Text to Speech is designed for content creators, developers, businesses, and individuals who require high-quality speech synthesis for various applications. It is suitable for entertainment, marketing, customer support, e-learning, and more industries.
Key features of Amazon Polly Text to Speech:
Wide selection of voices & languages
Synchronize speech
Streaming audio optimization options
Speech controls
Newscaster speaking style
Adjust the maximum duration of speech
Speech synthesis via API, console, or command line
Custom lexicons
Brand voice
Contact center integrations
Pros of Amazon Polly Text to Speech:
Reliable TTS services for various use cases such as chatbot audio, help desk queries, and interactive voice response (IVR).
Simple API operations that generate lifelike speech, allowing developers to build speech-enabled applications quickly.
Reasonable pricing for AWS customers, with free tier users receiving five million characters free every month for the first year.
High-quality voices can speak English and a foreign language in the same sentence.
Integration with popular platforms like WordPress and Medium through plug-ins makes creating audio content easy.
Cons of Amazon Polly Text to Speech:
Limited support for non-text input and non-audio output files.
No built-in speech recognition services like dictation, voice typing, or transcription are available through separate applications like amazon transcribe.
The user interface may be intimidating to non-developers, as generating speech with specific requirements requires manual entry of commands and knowledge of SSML tags.
Limited range of voice and language options compared to some other text-to-speech solutions.
Synthesized voices can sound robotic, lacking nuance and a natural human-like quality.
Technical challenges may arise when integrating it with other cloud providers.
Pricing:
Standard Voices - $4/million characters
Neural Voices - $16/million characters
Free
Standard Voices - 0 to 5 million characters
Neural Voices - 0 to 1 million characters
(calculated monthly | valid upto first 12 months)
11. TTS Reader
What is TTS Reader?
TTS Reader is a user-friendly online tool that converts text into natural-sounding speech, allowing users to listen to texts from various sources such as web pages, PDFs, ebooks, and custom input. With its intuitive interface and seamless experience, TTS Reader enhances multitasking, comprehension, and accessibility through the power of text-to-speech technology.
Who is TTS Reader for?
TTS Reader caters to a wide range of users, including individuals who prefer auditory learning, those with visual impairments, content creators, language learners, proofreaders, and anyone seeking a convenient way to consume textual content by listening.
Key features of TTS Reader:
Multilingual capabilities
Flexible configurations
Listen to web pages
Turn ebooks into audiobooks
Read along for speed & comprehension
Generate audio files from text
Pros of TTS Reader:
An intuitive user interface for easy text-to-speech conversion without needing file downloads or complicated apps.
Automatically highlights the text it narrates, making it easier to follow.
Pronunciation corrections and rich text formatting options for improved accuracy and readability.
Ability to skip paragraphs or lines while reading, allowing users to customize their listening experience.
Multilingual capabilities with natural-sounding voices in different accents and languages.
Cons of TTS Reader:
Limited voice customization options compared to some other text-to-speech solutions.
The free version may be limited, with additional features available through a premium subscription.
The alternative option of hearing the audio recording of a random interesting article may not be helpful for everyone.
It may not offer advanced features like voice cloning or real-time team collaboration.
Pricing:
Premium - $2/month
Free
Unlimited text reading
Online text to speech
Upload files, PDFs, ebooks
Web player
Webpage reading Chrome extension
Editing
Premium - $2/month
Ads free
Unlock features
Recording audio - for generating audio files from text
Commercial license
Publishing license
Better support from the development team
+ Everything in Free Plan
12. Microsoft Azure Text to Speech
What is Microsoft Azure Text to Speech?
Microsoft Azure Text to Speech is a cloud platform that utilizes machine learning and AI to convert written text into lifelike spoken words. It offers various neural voices in multiple languages, allowing developers to integrate natural-sounding speech capabilities into different applications. Whether building virtual voice-enabled assistants, enhancing accessibility features, generating audio versions of documents, or creating immersive experiences in media production, Azure Text to Speech provides the tools and resources to bring the text to life through high-quality speech synthesis.
Who is Microsoft Azure Text to Speech for?
Microsoft Azure Text to Speech is for developers, businesses, and individuals seeking customizable and lifelike text-to-speech capabilities. It caters to industries, including content creation, virtual assistants, accessibility, gaming, branding, and customer engagement.
Key features of Microsoft Azure Text to Speech:
Customizable neural voices
Fine-grained audio controls
Flexible deployment options
Custom voice
Pros of Microsoft Azure Text to Speech:
The free version offers up to five hours of audio and one custom voice model per month.
Microsoft's language processing system is highly advanced and can recognize even faint and distorted sounds in many cases.
Supports a range of languages and dialects, making it versatile for understanding different speeches.
Offers robust APIs for seamless integration with custom applications.
Impressive speech models were created using neural voices.
Translation services work well.
Built-in machine learning capabilities open up possibilities for various business use cases in the future.
Cons of Microsoft Azure Text to Speech:
Not user-friendly, with a complicated interface that requires substantial training to set up.
Pricing is costly, making it less affordable for individual users not on a company plan.
Different accents may pose challenges, although improvements can be expected with more data and reinforcement learning.
Slow return on investment due to the high price.
Limited community engagement and development, suggesting the potential benefit of open-sourcing some source code to foster further collaboration within the small community.
Pricing:
Neural:
Real-time & batch synthesis: $16/1M characters
Long audio creation: $100/1M characters
Custom Neural2:
Training: $52/compute hour (up to $4,992 per training)
Real-time & batch synthesis: $24/1M characters
Endpoint hosting: $4.04/model/hour
Long audio creation: $100/1M characters
Free
Neural - 0.5 million characters/month
13. Natural Readers
What is Natural Readers?
Natural Reader is a versatile program designed to assist users in accessing and comprehending written content through text-to-speech conversion. It offers features that allow users to convert text, PDF files, and various document formats into spoken audio. By leveraging AI voices, Natural Reader delivers a seamless reading experience with lifelike speech synthesis.
Who is Natural Readers for?
Natural Reader caters to a diverse range of individuals who can benefit from its text-to-speech capabilities. It helps students with learning difficulties, visual impairments, or reading challenges. Listening to the spoken content, students can enhance their comprehension, study more efficiently, and overcome reading barriers. Additionally, professionals who need to review documents or lengthy reports can use Natural Reader to save time and multitask effectively. Furthermore, individuals who prefer auditory learning or listening over reading can find Natural Reader a valuable tool.
Key features of Natural Readers:
200+ voices
Closed captions
Pronunciation editor
Synchronized reading
OCR camera scan
Voice styles
AI smart filter
Allows 20+ formats (to be converted into spoken audio)
Pros of Natural Readers:
Available as both an app and an online tool, providing flexibility for users.
Includes a WebReader widget for website integration.
Reasonably priced premium tiers for unlimited access to premium voices and additional features.
Supports multiple languages and voice genders.
Provides an alternative to professional proofreading with its accurate speech-to-text conversion.
Offers a website reading widget for enhanced accessibility.
It can be used for educational purposes with options for free student access.
Cons of Natural Readers:
The generated speech can sometimes sound stilted or unnatural.
The voices provided by Natural Reader are heavily used on YouTube, making them less unique.
Lacks randomized voice variations to maintain authenticity.
It does not offer regional accents, limiting the diversity of voice options.
May encounter difficulties with accurately pronouncing names, technical words, and historical texts.
Cannot upload voice recordings to the platform.
Rating:
Capterra - 4.5
Trustpilot - 2.7
Pricing:
Personal Premium - $9.99/month
Personal Plus - $19.99/month
Commercial Single - $99/month
Natural Reader comes with more plans and variable pricing!
We have listed the most popular ones.
Free
Unlimited use of limited free voices
Skip text (ignore text in parentheses/brackets)
Pronunciation editor
Auto-scroll
Account library
Personal Premium - $9.99/month
40+ non-AI Premium voices
8 languages
Personal Plus - $19.99/month
100+ human-like AI plus voices (500K characters per day)
40+ non-AI Premium voices
20+ languages
Commercial Single - $99/month
Commercial license for audio distribution
25+ Languages, 250+ AI Voices
Download 1 million characters per day
AI voices with human emotions
Advanced text and pronunciation editors
14. IBM Watson Text to Speech
What is IBM Watson Text to Speech?
IBM Watson Text to Speech is a robust text-to-speech service that converts written text into natural-sounding speech. It utilizes advanced deep-learning techniques to generate neural voices, producing high-quality and expressive speech output, enabling applications and systems to deliver engaging and lifelike voice experiences.
Who is IBM Watson Text to Speech for?
IBM Watson Text to Speech caters to a wide range of users and industries. Developers can leverage its capabilities to enhance voice-driven applications such as chatbots, virtual assistants, and interactive voice response (IVR) systems. Businesses can utilize it to create audio versions of documents, websites, and multimedia content for improved accessibility and user engagement.
Key features of IBM Watson Text to Speech:
Real-time speech synthesis
Custom voices
Controllable speech attributes
Voice transformation
Customized word pronunciations
Pros of IBM Watson Text to Speech:
User-friendly interface and ease of use
Excellent support for multiple languages
Accurate and precise text-to-speech conversion
Ability to gain insights from text data through speech conversion
Cons of IBM Watson Text to Speech:
Occasional mispronunciation of words
Limited language support compared to other text-to-speech solutions
Lack of sentiment analysis for better contextual understanding
Need for further improvements in accuracy and processing time
Rating:
G2 - 4.1
Pricing:
Standard - $0.02/ thousand characters
Premium - custom pricing
Free
10,000 characters/month
Standard - $0.02/ thousand characters
Real-time speech synthesis
Expressiveness
Controllable speech attributes
Voice transformation
Customized word pronunciations
Premium - custom pricing
Usage and training data are private + stored in an isolated single-tenant environment.
High availability and service level uptime guarantee
IBM cloud service endpoints
Custom voice (beta)
+ Everything in Standard Plan
15. Narakeet
What is Narakeet?
Narakeet is a text-to-speech platform designed to simplify the process of creating voiceovers for audio and video content. It offers an alternative to traditional voice recording, editing, and synchronization tasks. Narakeet also serves as a video presentation creator, enabling the transformation of presentations from PowerPoint, Google Slides, or Keynote into videos with integrated voiceovers.
Who is Narakeet for?
Narakeet caters to a diverse user base seeking efficient text-to-speech solutions for audio and video projects. This includes content creators, educators, marketers, and businesses aiming to enhance their multimedia content creation process. Whether producing training videos, marketing content, tutorials, or streamlining video production using APIs and command-line integration, Narakeet accommodates a wide range of content creation needs.
Key features of Narakeet:
600 voices
90 languages
Pitch transformation
Video creation capability
API access
Pros of Narakeet:
Top-up on-demand pricing without set-up fees or recurring costs.
Provides video creation capabilities along with text-to-speech.
Cons of Narakeet:
User Interface needs improvement.
Some voices may sound robotic.
Voice cloning is not present.
The free version may be limited, with most features available through paid plans.
Pricing:
30 minutes - $6
300 minutes - $45
1000 minutes - $100
2500 minutes - $200
10000 minutes - $500
Free
20 conversions
Max 1 KB audio script length
Max 10 KB video script length
Max 30 video scenes
Max 10 MB file upload size
Loved by content creators around the world
10,000,000+
people creating videos for social media, training, courses and much more.
4.8/5
satisfaction from 5,500+ reviews from G2 and Capterra
5x
productivity improvement and create videos faster than traditional methods.