
When Zuckerberg Isn't Surfing...
Do you know what Mark Zuckerberg does when he isn't wake surfing in a tuxedo at his Lake Tahoe mansion? Well, aside from this, he's battling it out with Google and OpenAI for AI supremacy. Just recently, Meta released their biggest large language model yet: Llama 3.1. It's free, mostly open-source, and it's got everyone talking.
The Guts of Llama 3.1
Llama 3.1 is a mammoth model trained over months using 16,000 Nvidia H100 GPUs. The cost? Hundreds of millions of dollars and enough electricity to power a small country. The result? A 405 billion parameter model with a context length of 128,000 tokens. Early benchmarks suggest it outshines OpenAI's GPT-4 and even Claude 3.5 Sonnet in some areas.
Starting today, open source is leading the way. Introducing Llama 3.1: Our most capable models yet. Today we’re releasing a collection of new Llama 3.1 models including our long awaited 405B. These models deliver improved reasoning capabilities, a larger 128K token context… pic.twitter.com/1iKpBJuReD
— AI at Meta (@AIatMeta) July 23, 2024
Three Sizes Fit All
Llama 3.1 comes in three sizes: 8B, 70B, and 405B—where 'B' stands for billions of parameters. Generally, more parameters mean a model can handle more complex patterns, but this isn't always the case. For instance, GPT-4 is rumored to have over a trillion parameters, but exact numbers are kept under wraps by companies like OpenAI.

What Makes Llama 3.1 405B Special?
1. Sheer Scale and Performance
Llama 3.1 405B is a colossal model with 405 billion parameters. Size matters, but it's also about how you use it, and this model knows how to flex its neural networks.
2. General Knowledge and Reasoning
Llama 3.1 405B excels in general knowledge, steerability, math, and tool use, challenging proprietary heavyweights like GPT-4 and Claude 3.5 Sonnet. Here’s the benchmark results shared by Meta:
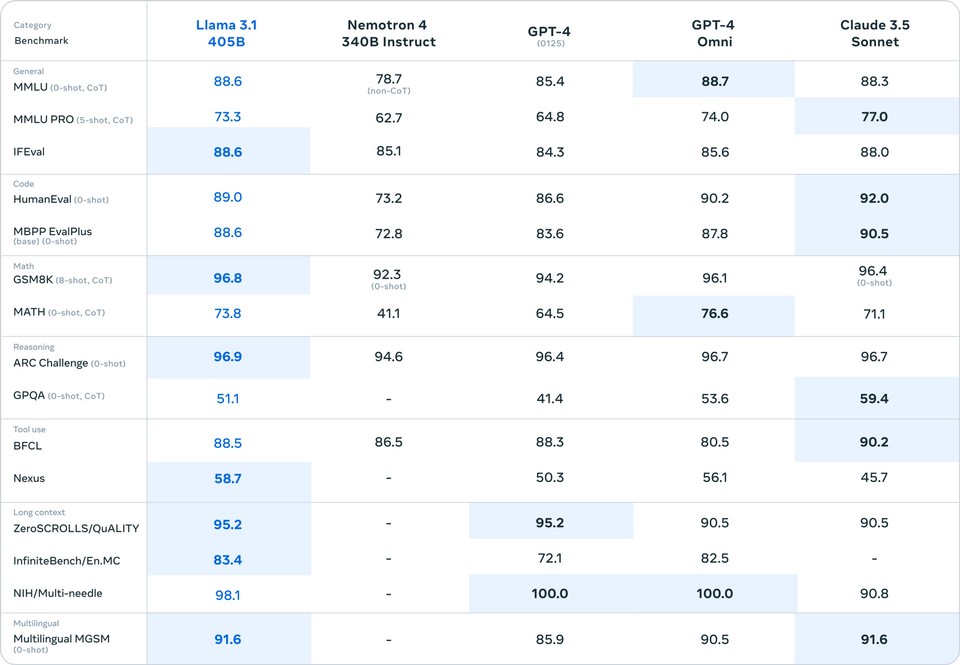
3. Multilingual Mastery
This model isn't just an English-language savant. Llama 3.1 405B speaks eight languages (English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai) fluently, making it a multilingual powerhouse.
4. Crazy Context Length
With a 128K token context length, Llama 3.1 405B has a photographic memory for entire books, setting a new standard for context length.
5. Open Source (Sort of)
The exciting part about Llama is its quasi-open-source nature. You can monetize it as long as your app doesn't hit 700 million monthly active users; at this point, you'll need a license from Meta. The training data isn't open-source and might include everything from your blog posts to your 2006 Facebook updates. However, the model's code is accessible—just 300 lines of Python and PyTorch, utilizing Fairscale to distribute the training load across multiple GPUs.
6. Developer's Dream
The fact that the open model weights are a huge plus for developers. You no longer need to pay exorbitant fees to use the GPT-4 API; instead, you can self-host your own model. Hosting the big model isn't cheap—I tried using Olama to download and use it locally, but with 230 GB of weight, even my RTX 4090 couldn't handle it. Thankfully, you can test it for free on platforms like Meta, Gro, or Nvidia's Playground.
Early Feedback: Mixed Reactions
Initial feedback from the internet suggests that while the big Llama might be underwhelming, the smaller models are quite impressive. The real power of Llama lies in its ability to be fine-tuned with custom data. This flexibility means we'll likely see some amazing, uncensored models in the near future.
holy cow @GroqInc + @AIatMeta Llama 3.1 405b we asked it what the best sausages in the world were -- this is all real time and literally just did it the world is going to get so crazy so fast@JonathanRoss321 this is just bonkers pic.twitter.com/CetWrLvCeZ
— AI For Humans Show (@AIForHumansShow) July 23, 2024
Open source models are great but they have to be accurate and perform. It was easy to mislead Llama 3.1 pic.twitter.com/HMYIdwzVQH
— Amit (@Amitmina) July 29, 2024
I turned Llama 3.1 into my new phone assistant. It can answer anything, and look at how fast it does it using Groq’s API 🤯 pic.twitter.com/dmlQ2gzSfu
— Alvaro Cintas (@dr_cintas) July 25, 2024
Testing the Waters: GPT 4o vs. Llama 3.1 vs. Claude 3.5 Sonnet
Testing the Waters, I decided to put Llama 3.1 to the test by comparing its ability to generate a YouTube Shorts script against GPT-4 and Claude 3.5 Sonnet. The task was to create a script focused on the "2-Minute Rule" productivity hack, and I rated each script based on parameters important for virality (0-10). Here are the results:
Script by GPT-4o
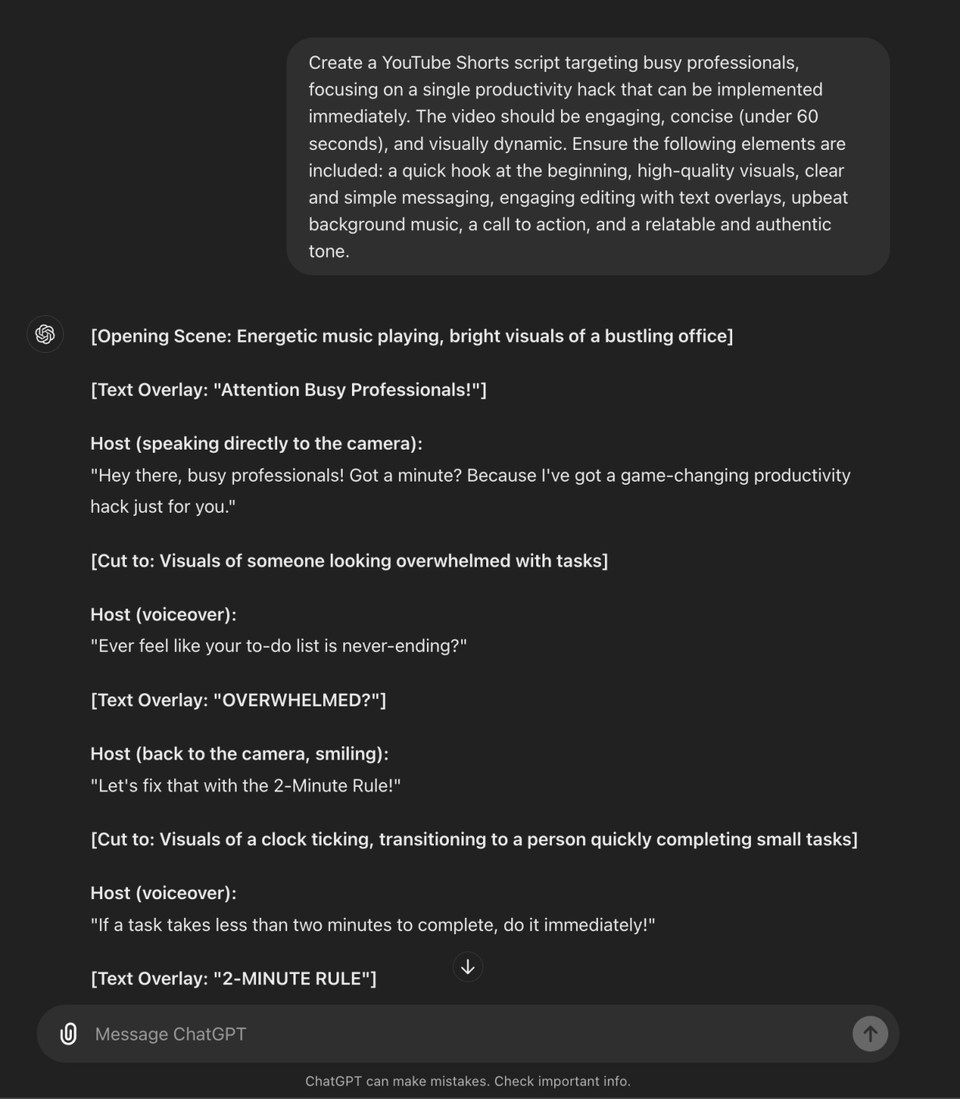
My Rating: 9/10
GPT-4o delivered an engaging and well-structured script, complete with energetic music, engaging visuals, and clear calls to action. It effectively captured the viewer's attention and maintained a smooth flow throughout. The inclusion of multiple text overlays and visual transitions helped reinforce the message, making it highly likely to go viral.
Script by Claude 3.5 Sonnet
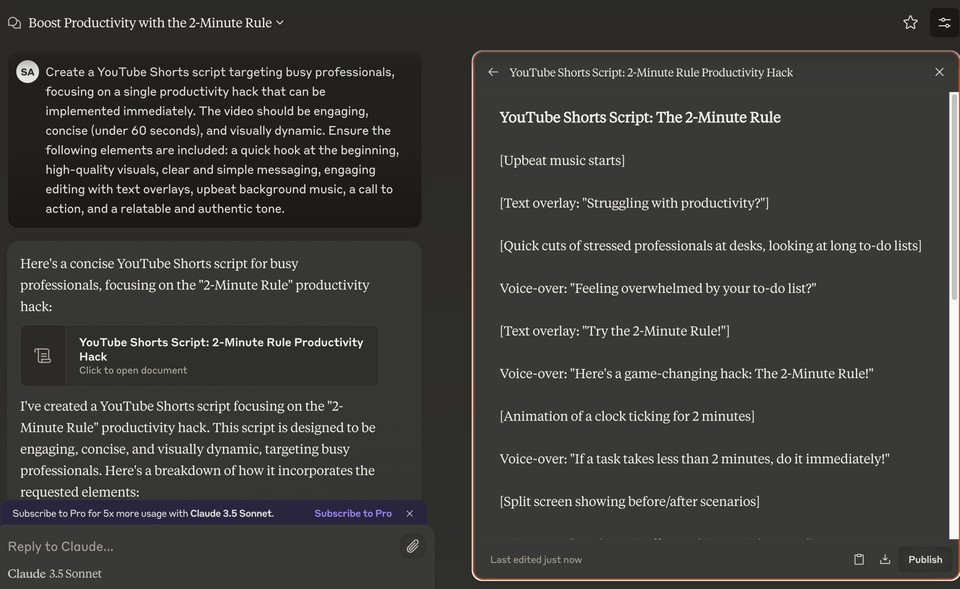
My Rating: 8/10
Claude 3.5 Sonnet's script was concise and focused, with a strong emphasis on visual storytelling. The use of split screens and before/after scenarios added a dynamic element, making the content visually appealing. However, it lacked the same level of direct engagement with the audience as GPT-4's script, slightly reducing its potential for virality.
Script by Meta Llama 3.1

My Rating: 7/10
Llama 3.1 provided a solid script covering all the essential points of the productivity hack. While it was clear and informative, the script felt less polished compared to the others. The transitions and visual cues were less dynamic, and they didn't capture the viewer's attention as effectively. It has potential but needs refinement to achieve the same level of virality.
While Llama 3.1 shows promise, it still lags behind GPT-4 and Claude 3.5 Sonnet in terms of creating highly engaging and viral content. The model's flexibility and open-source nature remain its standout features, but there's room for improvement in content generation.
Final Words: Reflecting on AI Progress
It's fascinating how multiple companies have trained massive models, yet they seem to plateau at the same level of capability. OpenAI made a significant leap from GPT-3 to GPT-4, but since then, advancements have been incremental.
The Reality of AI Today
Last year, Sam Altman urged the government to regulate AI for humanity's safety, yet we haven't seen the dystopian AI takeover he warned about. AI hasn't even replaced programmers yet! It's like expecting light-speed engines after jet engines but getting stuck with propellers.
Meta's Surprising Contribution
Strangely enough, Meta might be the only major tech company keeping it real in the AI space. While there might be ulterior motives, Llama represents a significant step forward and perhaps a redemption arc for Zuckerberg.


